提取PPT与Word里的所有图片
2020/04/13
共 510 字
约 1 分钟
归档: 技术
你可能会用上的技巧
简短的教程
如果有一天,你需要提取一个PPT或者word里面的所有图片,你可以这么做,以PPT为例:
复制一份,修改后缀为zip(不显示后缀的自己去百度)

解压这个压缩包
解压后可以看到类似以下的目录,图片在PPT/media中

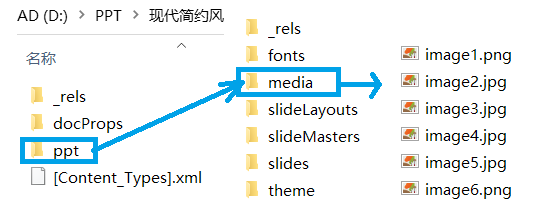
同理,如果是word则在word/media中
如果是2003版本的office文件,解压后将会是没有后缀的文件:
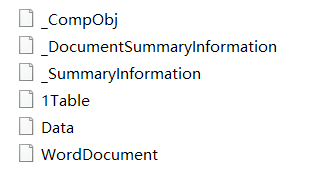
这是因为新版才使用了xml与zip技术
判断文件是旧版还是新版
97-03的是旧版,后缀如doc、ppt、xls
2007-现在的是新版,后准如docx、pptx、xlsx
没关系,只要电脑上的office是2007以及以上的版本,都可以把旧版转换为新版
打开文档,点击菜单栏的文件,可以看到有一个兼容模式的转换,点击转换,弹出提示,点击是,再ctrl+s保存一下,这时候文件就转换成了新版本,便可以接着改后缀解压的操作。

一个延伸
新版的office文档有着诸多看得到的好处,比方说
同样内容的文件,因为采用了压缩技术,新版的体积更小
最新版的PPT可以直接嵌套音频与视频,复制的时候不用复制文件夹
刚刚的提取media的内容
其实epub也是一个压缩包,解压后基基本都是这样的目录结构
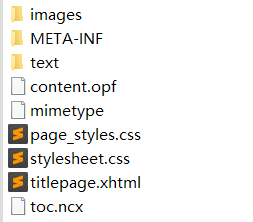
images中包含整本书的图片,text中包所有文字。
点进去text可以看到,其实每一个html就是一个章节,直接用浏览器打开即可查看,具体样式可以在两个css里面调整。懂前端的是不是瞬间就明白了。照这个思路写一个网页端的epub阅读器并没有多难,字体大小背景颜色,一系列调整完全可以用javascript实现。
我给自己挖了个巨坑。
留言