爬虫实战:爬取挑战题答案
只是能用。
既然没精力系统地、稍微深入地学一遍Python3,那仅仅是能用也好。需要的时候,能够有得用,就足够了。所以程序基本不加错误校验。其实就是懒
从头说起
无意看到个Python爬虫的教程,看了下用现成的库实现起来还蛮简单的。爬虫算是玩编程中,为数不多的花少量精力就能获得成就感的项目吧。
但是要知道的是,基础的爬虫简单,有时几行代码就够了,那是因为网站什么反爬虫机制都没加;而真正以写爬虫为工作的都是高高手,大规模的数据量,绕过复杂的验证,甚至涉及到网络安全,要学的东西太多了,现在的我还真学不来。
所以看了几个教程,跟着爬了下猫眼电影Top100之类的,已经准备收手了,等以后真的需要数据的时候,把现成的代码改一下基本就能用了。这时候我看到了个网站,有学习强国挑战答题的题库。心想,刚好派上用场。
PyCharm
既然从头说起,那就从工具说起。之前一直傻傻地用原生的Python的编辑器,我又不是大神,能大大提高效率的工具干嘛不用,花时间浪费在编辑器上面不值得,所以有个智能点的开发工具,无疑大大提高敲代码的体验。C/C++有codeblocks,Python有PyCharm。这个IDE(集成开发环境)并不包含Python环境,还是需要先手动安装Python,勾上添加到path就可以不用手动添加环境变量了。
引入一些库
对于库文件的引入,Python比C方便多了,在cmd中用pip包管理工具,可以轻松地直接下载安装丰富的库文件。
一切都要先换源。如果用官方的源下载,几kb/s足以让你怀疑人生。
pip国内的一些镜像阿里云:
https://mirrors.aliyun.com/pypi/simple/
中国科技大学:
https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban)
http://pypi.douban.com/simple/
清华大学:
https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学:
http://pypi.mirrors.ustc.edu.cn/simple/
永久更改镜像源的方法:在user目录中创建一个pip目录,如:C:\Users\Jack\pip,新建文件pip.ini,内容如下
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = https://pypi.tuna.tsinghua.edu.cn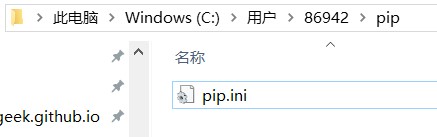 然后我们这次用到的一些库
然后我们这次用到的一些库pip install beautifulsoup4
pip install requests安装包:
pip install SomePackage # 最新版本
pip install SomePackage==1.0.4 # 指定版本
卸载包:
pip uninstall SomePackage
查看可升级的包:
pip list -o
升级包:
pip install --upgrade SomePackage
网页分析
打开题库的第一页:https://www.3gmfw.cn/article/html2/2019/09/09/486867.html
打开开发者工具,使用选择工具定位到答案内容,发现所有答案都放在一个p标签内,那就好办了,直接用BeautifulSoup select第4个p标签的内容就好了。
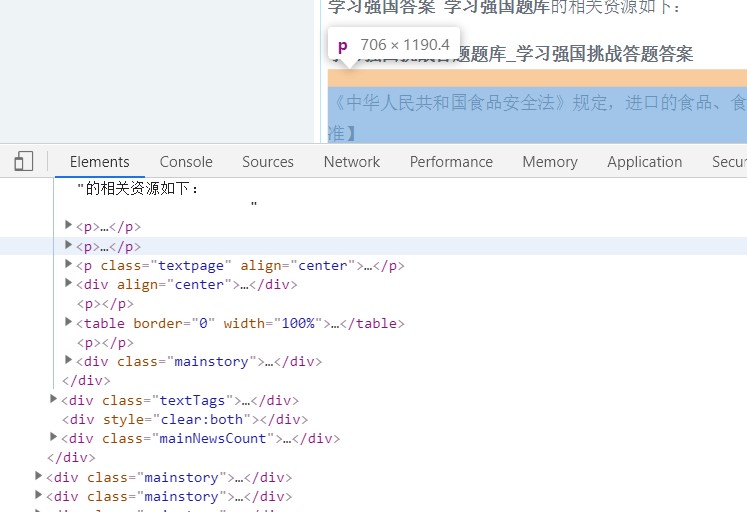
爬取并保存第一页的源码如下:
import requests
from bs4 import BeautifulSoup
headers={
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
html = requests.get('https://www.3gmfw.cn/article/html2/2019/09/09/486867.html',headers=headers)
html.encoding = html.apparent_encoding
soup = BeautifulSoup(html.text,'lxml')
box = soup.find(class_='NewsContent')
answers = box.select("p:nth-of-type(4)")
print(answers)
for answer in answers:
fo = open("anwserpage1.txt", "a+",encoding='utf-8')
fo.write(str(answer))
fo.close()本以为就是这么简单,用典型的循环替换页码就可以完成所有页面的爬取了。正这么操作时,出问题了,后面爬出来的类容都是空的。一看html代码发现,第二页到后面的答案,并不是放在p标签里面!看看他是怎么操作的: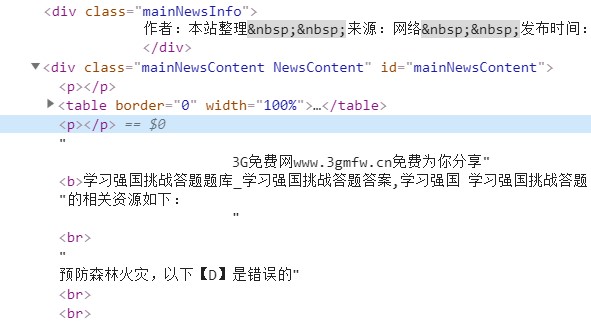
他把答案内容放在两个空的p标签对之间,实际上是放在一个div里面,而这个div包含着很多与答案无关的文本内容,把他们全部抓下来可不是什么好方法。
于是想到了用正则表达把内容筛选出来,可以找到规律,每页答案的开头都有“相关资源如下”的字样,当然如果不介意多写入些与答案无关的内容,直接利用两个<p></p>就可以达到目的了。这里主要利用开头的如下以及结尾处的<p></p>爬取2-46页的代码如下:
import requests
import re
headers={
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
for number in range(2,47):
url = 'https://www.3gmfw.cn/article/html2/2019/09/09/486867_' + str(number) + '.html'
html = requests.get(url,headers=headers)
html.encoding = html.apparent_encoding
rule = re.compile('.*?如下.*?<br/>\\n(.*?)<p></p>',re.S)
answers=re.findall(rule,html.text)
# print(answers)
print("写入第%s页"%number)
for answer in answers:
fo = open("leananswer.txt", "a+", encoding='utf-8')
fo.write(str(answer))
fo.close()此时已经可用正常爬取所有答案,多余的<br>可用在word或者sublime text3中查找并删除全部,这样使用就方便了。
同时也发现个问题,太慢了。大概5s爬取一页,这不应该。
第一反应觉得可能是请求头的问题,但是把Request Headers几乎全补上了,还是很慢,那问题就不在这了。
然后觉得是正则表达的问题,但是正则表达式再慢也不应该有这么大影响。我能想到的唯一有可能有影响的是中文的GBK编码,于是改了下正则表达的开头,:\\r\\n,这个是“相关资源如下”后面的字符,这下没有中文了,但是很可惜,速度还是很慢。
会是算法的问题吗,实际上获取数据就一个for循环,没什么好优化的。
所以做了个试验看看问题到底出在哪:看看获取每个页面的速度到底有多快。把正则删掉,每次直接输出网页的html代码,结果发现输出非常快,那么问题很明显就是出在正则表达式上。
于是展开了长时间的排查,一切都怪自己学艺不精,最后发现是一个问号的问题,看看菜鸟教程怎么写的:
? 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。
* 匹配前面的子表达式零次或多次。
上面代码的基础上,只需删掉一个问号,程序就可以变得非常快了。
完全意想不到,因为看过几个教程,.*?这样的组合实在太常见了,以为不会出问题。估计这里是非贪婪的问题,正确匹配完一次之后又进行了几次尝试,所以才会这么慢。
由于发现不加请求头一样可以爬取,就干脆删掉了,贴上最终的能用的代码:
import requests
import re
from bs4 import BeautifulSoup
for number in range(2,47):
url = 'https://www.3gmfw.cn/article/html2/2019/09/09/486867_' + str(number) + '.html'
html = requests.get(url)
html.encoding = html.apparent_encoding
rule = re.compile(':\\r\\n(.*)</p><p',re.S)
answers=re.findall(rule,html.text)
print("写入第%s页"%number)
for answer in answers:
fo = open("leananswer.txt", "a+", encoding='utf-8')
fo.write(str(answer))
fo.close()最后
代码仅止于能用,连请求是否成功的判断都没有。
本来环境配置应该分开写的,所以这篇文章非常的长。但是这是事后补上的,所以还是丢失了部分细节,仅仅作为个记录,以后需要用到某些代码段方便查找罢了。
其实中途还经历了长时间的抓包,企图看出为什么这么慢,但是也没看出个所以然来,所以就不记录了。
至于实用性,这个题库还是挺全的,实际使用勉强满意,日后这个网站如果不再更新这个题库,估计代码也不会更新了。
中秋快乐。
留言